
How DDAI Turns Fragmented CRM Data into Enterprise-Grade Analytics at Scale
CRMs Are Built to Flex—Not to Standardize
Modern CRMs are designed to adapt to how a business operates—not force it into a rigid structure. Custom objects and properties are features, not bugs. HubSpot exemplifies this flexibility. Teams can create objects like “Installations” or “Partners,” redefine lifecycle stages, and model their business however they choose. The CRM becomes a direct reflection of operations. Operationally, this is powerful. Analytically, it creates a problem: flexibility comes at the cost of standardization.
Over time, inconsistencies emerge. Fields get duplicated or renamed, definitions drift, and relationships become unclear. The system still functions—but the data becomes harder to reason about cleanly.
For One Company, This Is Manageable—But Not Free
Within a single company, this complexity is contained by context. Teams understand their data, and when reporting breaks, a data team steps in to normalize it—cleaning fields, defining transformations, and rebuilding consistency. It works, but it requires ongoing investment: engineering time, pipeline maintenance, and constant alignment between business logic and data. CRM customization creates data chaos. It’s manageable—but only because a single company can afford to fix it.
At Scale, the Model Breaks
What works for one company fails in a one-to-many system. At DDAI, every customer has a different schema. Objects, definitions, and relationships vary widely—one company’s “Installations” is another’s “Projects,” and even shared terms rarely mean the same thing. There’s no standard to rely on and no practical way to normalize each instance manually. So we did something different...and innovative
The Shift: Separating Structure from Meaning
Our solution is to separate what’s consistent from what’s variable—and define how variability should be understood. At the center is a canonical data model built on shared entities like customers, deals, invoices, payments, and subscriptions. This layer unifies HubSpot, Stripe, and QuickBooks and defines core metrics like ARR, churn, CAC, and LTV. It stays clean and consistent across all customers.
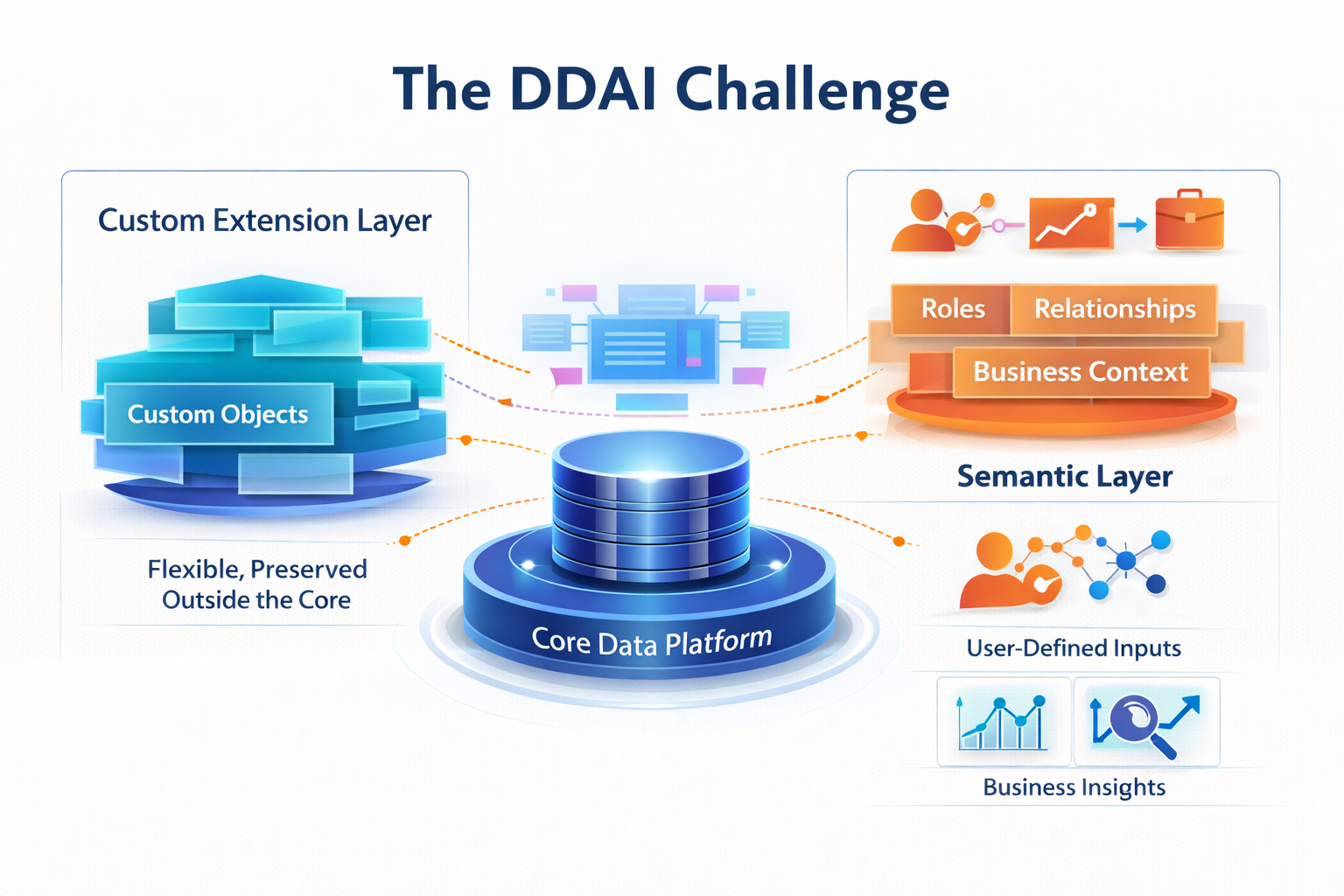
Customer-specific customizations live outside the core in a flexible extension layer. Custom objects and properties are preserved without forcing them into a rigid schema, preventing schema explosion while retaining full data fidelity. But structure alone isn’t enough—meaning has to be defined. So our semantic layer captures object roles, relationships, and business context, allowing the system to understand how data should be used, not just how it’s structured. And because meaning can’t be fully predefined, DDAI also exposes this layer to users—so they can define key fields and relationships themselves, bringing interpretation closer to the business and eliminating constant custom engineering.
Why This Matters for AI
AI doesn’t fix messy data—it amplifies it. Without structured meaning, outputs are inconsistent and unreliable. In DDAI’s architecture, AI operates on a defined semantic layer—not raw fields—so it can produce consistent, explainable answers across systems. That’s what makes cross-system analytics actually work.
The Real Takeaway
CRM flexibility isn’t the problem. The problem is assuming it can be layered into a standardized model without trade-offs. At the single-company level, that creates manageable complexity. At scale, it creates fragmentation.
The answer isn’t less flexibility—it’s better architecture: a clean core, a controlled extension layer, and a semantic system that makes variability usable. This is where DDAI leads. By combining a purpose-built data model with an AI-native semantic layer, we deliver consistent, explainable, enterprise-grade analytics—out of the box.
👉 Want to see how it works? Book a demo.